Map My Mountains
1 February 2019 (Updated on: 11 February 2022)
Introduction
In Jan 2018, shortly after my graduation, I was offered a contract to work for a team of PhD students lead by Prof. Piero Fraternali. The team operated as part of the “Department of Electronics, Information and Bioengineering” inside the university of Politecnico di Milano.
I was hired to develop a Geographical Information System (GIS) from scratch to provide good quality data for an ongoing research project. The research project goal was to develop a Machine Learning (ML) algorithm to recognize mountain peaks from the Digital Elevation Model (DEM) of the earth. Essentially a fancy way to find mountains using the 3D model of the earth.
The outcome of any ML project is highly dependent on the quality of data used as input therefore it is worth to have a good pipeline in place that can clean and filter data.
Furthermore we planned to use the data produced by the new GIS for “Peaklens” (created by the same team) which is an app that recognizes mountains using the camera of your smartphone. It works great and it is completely free, you should try it out for yourself!
The Project
The project consisted of three main tasks:
- Create a data model to store geographical data coming from different data sources with annotations and corrections.
- Create multiple data pipelines to import publicly accessible geographical data sources into our data model.
- Create a web application to allow human annotators to review the data and validate it through crowdsourcing.
1. Data Model
I kicked off the project with an iterative process of:
- Collecting and defining the requirements as use cases.
- Designing a data model to account for the use case.
- Simulating the usage of the data model and finding new questions for the stakeholders.
The process required an interactive process with the people involved in the ongoing ML research project.
I sketched the data model as Entity-Relationship and iteratively improved until it satisfied all the requirements the system needed to support. You can see the final result here.
We had informal meetings to decide which database to use. The alternatives were either a traditional relational database (PostgreSQL) or a NoSQL document database (MongoDB).
In the end we decided to go with PostgreSQL because:
- no need to scale (storage expectations <100GB, user base <100 people)
- it supports geometrical types out of the box which are convenient for geographical data (points, polylines, polygons)
- strong data consistency (the schema enforces types and relations)
- we expected the need for multiple JOINs between different data sources and user annotations
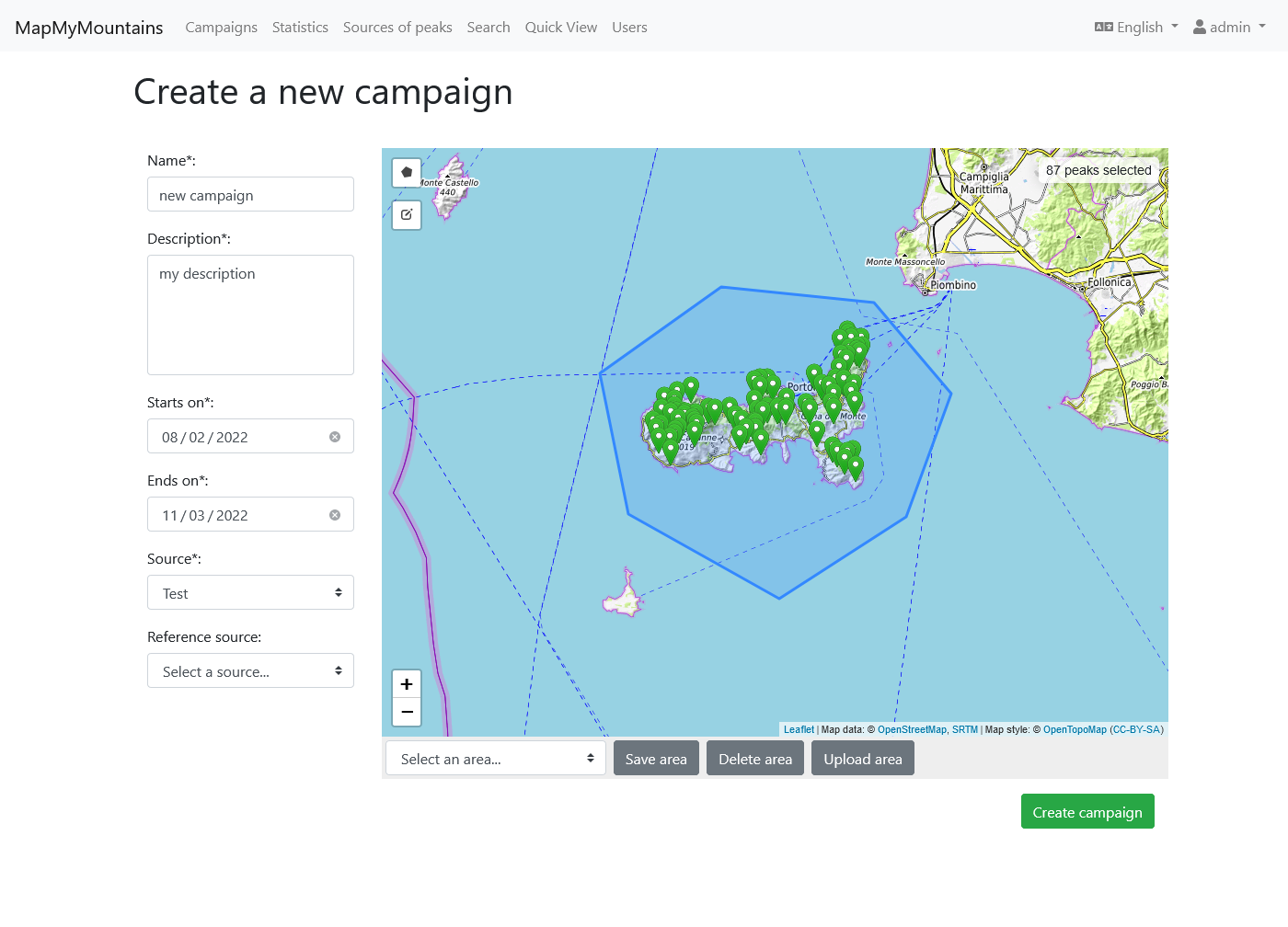
2. Import from Geographical Data Sources
Once the data model was defined, the next step was to import as much data as possible. For this reason I investigated publicly accessible geographical data sources, studied their format and APIs, wrote and tested scripts to download their data.
The data model is able to store reference to the unique original identifier of each downloaded element so we could have potentially contributed back to each source following the Open Source spirit of giving back to the community.
By the time my contract ended I had written scripts to import mountain peaks from:

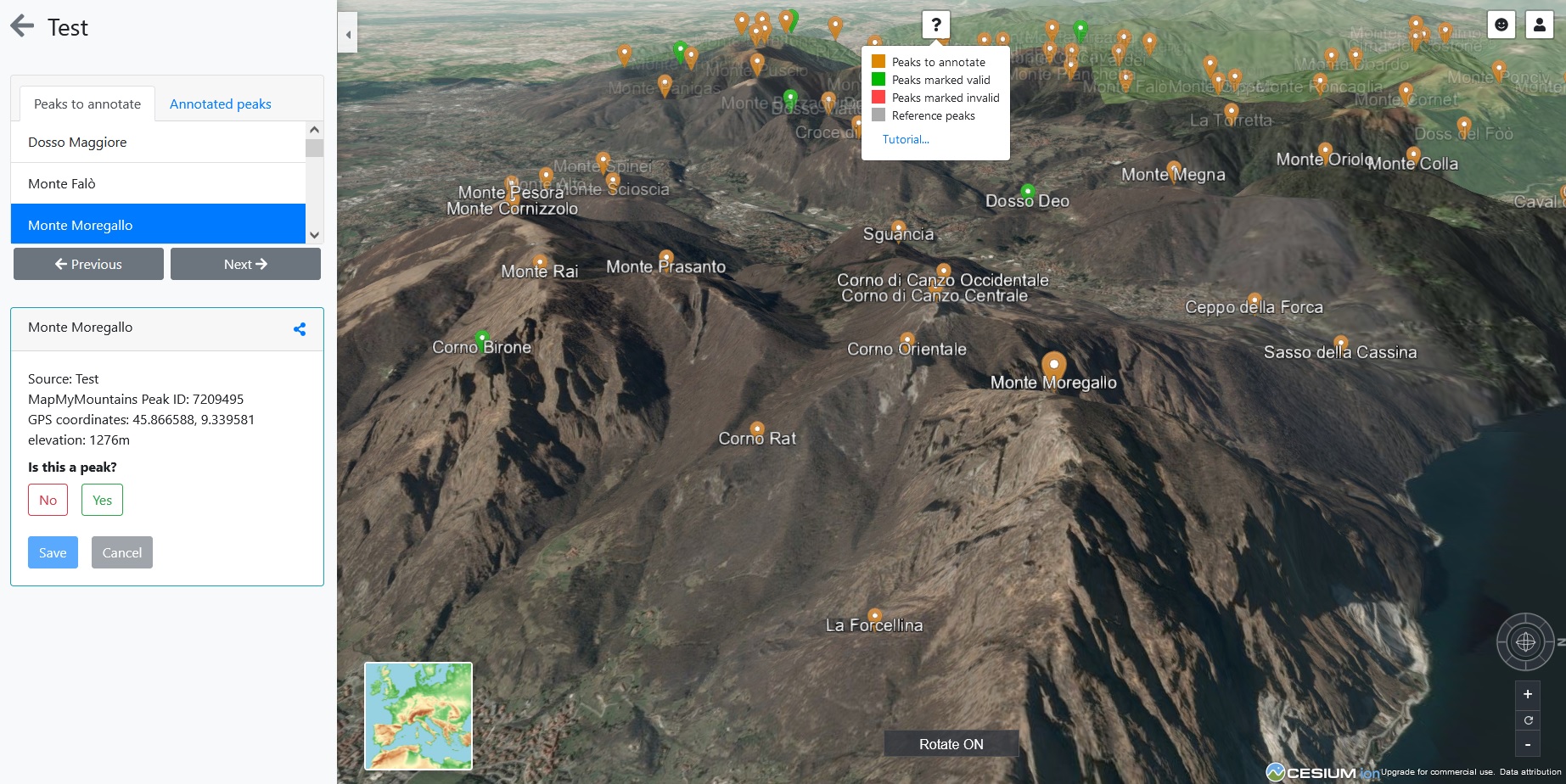
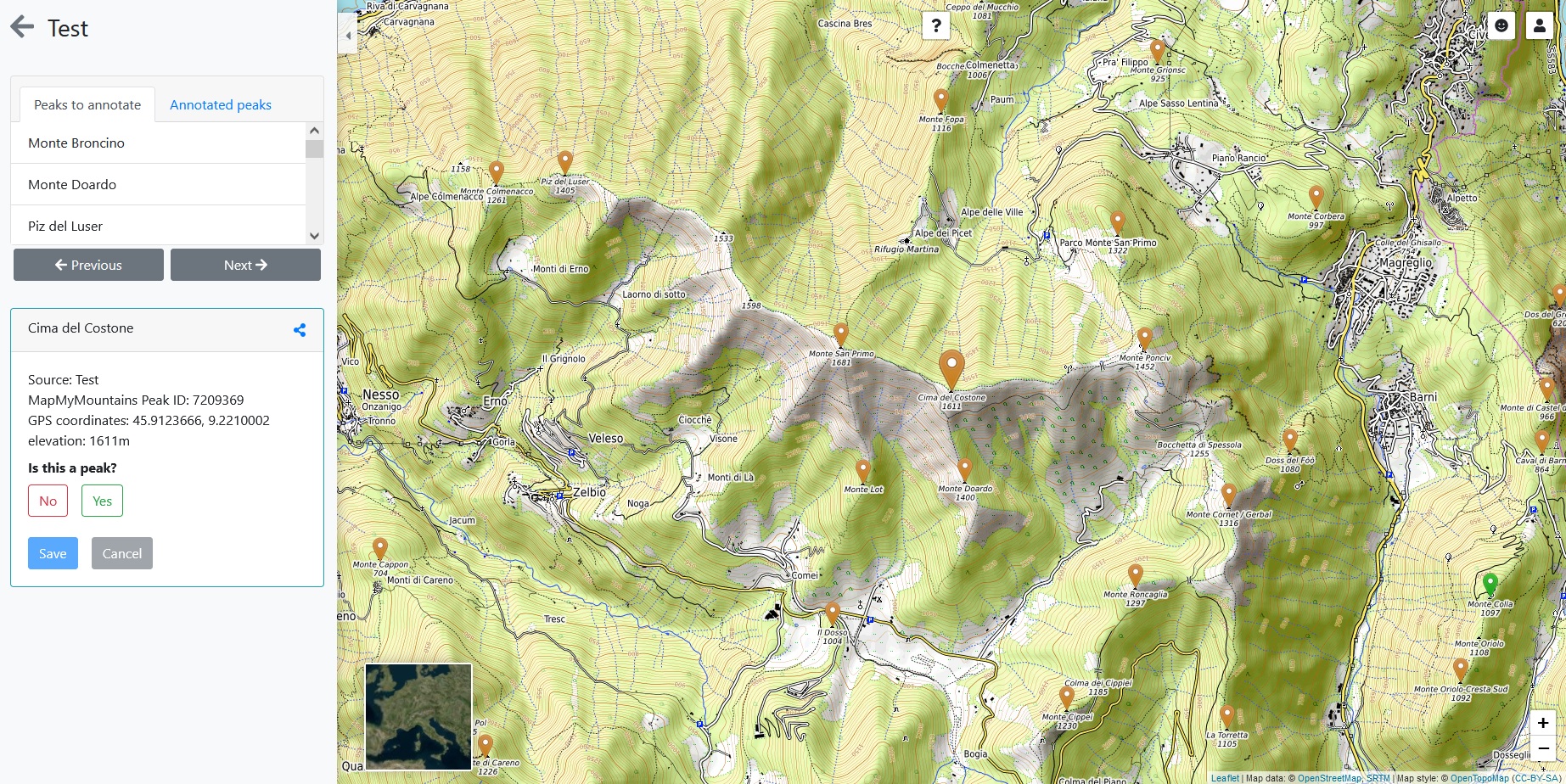
3. Crowdsourcing Web App
The last task was the development of a Web App to annotate and review the data. Here you can peek the requirements specification document.
For the tech stack we agreed on using Node Js for back-end and Vue Js for frontend, the main reason being keeping all the code base in Javascript. The web app was hosted on the private cloud of Politecnico di Milano which is based on Open Stack.
For visualizations I have used Cesium Js which provides interactive 3D globes and Leaflet Js for rendering 2D maps. For the UI I have used BootstrapVue which provides ready to use Vue components based on Bootstrap.
For the development process I have followed an Agile approach with 2 weeks sprints after which I demoed the new features and collected feedback for the next iteration.
I really enjoyed working on this project because it allowed me to get full-stack development experience and also some planning skills as I was fully entrusted in defining my tasks and delivering them. During the project I also mentored a student who then helped me in some development tasks.
Live Demo
Before writing this article I decided to host a live instance of the Web App on Amazon AWS so that you can could see it live. I contacted Piero who kindly gave me permission to share the source code of the Web App for my portfolio, since it is not in use anymore.
“Resuscitating” a project that is “only” 3/4 years old proved to be more difficult than I thought.
I expected it to be fully working as I left it. However simply running it locally, using the latest stable Node Js resulted in some weird connection issues with the database that kept making my unit tests fail. I traced it back to the NPM library I used to connect to the DB (pg-promise) and updating it fixed the problem promptly.
I have also fall victim of a strange bug where the Vue CLI Service did not exit after finishing building the production bundle. This didn’t cope well with my goal of having a CI pipeline because it makes the automated process hang and timeout. I fixed it again with more targeted package updates.
I have tried updating all the NPM packages at once but that resulted in many incompatibilities appearing between my code and the new packages. Since I did not want to spend time fixing code, I only did targeted updates for specific packages.
This proved me how unstable is the entire NPM/Node Js ecosystem. Today I rather use a self-contained web framework that provides everything out of the box such as ASP.NET, Django, Ruby on Rails, or Laravel, and stay away from the dependency hell that is the Javascript ecosystem with NPM.
For hosting the Web App I have used: Amazon RDS for the database (I created a PostgreSQL instance), Amazon Elastic Beanstalk for the back-end REST API, and Amazon S3 for the front-end (configured to serve a static website). Both the back-end and front-end are served on vanilla HTTP to avoid having to deal with SSL certificates.
Overall the setups works quite nicely, it fits well within the limit of the Amazon Free Tier. It also has continuous deployment thanks to Github Actions.
You can find the live demo at: http://mapmymountains.aradaelli.com
Source code: https://gitlab.com/wds-co/mapmymountains
Credits
I want to mention the whole team at Politecnico di Milano with whom I have worked from 2018 to 2019. In 1 year I have learned a lot and I still have a great relationship with them:
- Piero Fraternali (Website-Linkedin-Google Scholar)
- Chiara Pasini (Linkedin-Google Scholar)
- Darian Frajberg (Linkedin-Google Scholar)
- Carlo Bernaschina (Website-Linkedin-Google Scholar)
- Nahime Torres (Linkedin-Google Scholar)
- Sergio Herrera Gonzalez (Linkedin-Google Scholar)
- Federico Milani (Website-Linkedin-Google Scholar)